MicroSoft 在AAAI2022的一篇文章,将ViT中的attention机制替换为无参数的shift操作,在几个主流任务中也取得了相当好的结果——attention机制或许并非ViT成功的关键因素。
论文地址:https://arxiv.org/pdf/2201.10801.pdf
开源代码:https://github.com/microsoft/SPACH
Introduction
自AlexNet起,CNN统治了CV领域近十年。2020年,ViT的出现撼动了CNN的统治力,其在众多CV任务上都有超越CNN的表现。但ViT中真正有效的机制仍不清楚。
一些传统观点认为attention机制是ViT成功的关键,因为self-attention机制可以帮助模型聚合任意位置的特征。与CNN相比,attention机制有以下优点:
- 可以同时捕获近距离和远距离依赖
- 交互是动态地取决于两位置各自特征的,而不受限于卷积核
实际上,一些ViT变体证明了即使没有以上优势,模型仍然效果很好。首先,全局的、完全的依赖可能并非无法避免的,许多ViT提出使用局部attention机制来限制感受野——Swin Transformer、Local ViT,证明局部attention并不会限制模型的性能。此外,MLP-Mixer证明了动态聚合的机制也收效甚微,用MLP代替了attention layer,在ImageNet上仍然领先。
本文尝试构建0参数、0计算、无全局视野、无动态的模型,从概念上说,必须通过一些人工规则建模空间关系。本文采用最简单Shift操作。将标准ViT的attention+FFN架构中的attention替换为shift,构建了ShiftViT,取得了高于Swin Transformer的效果。
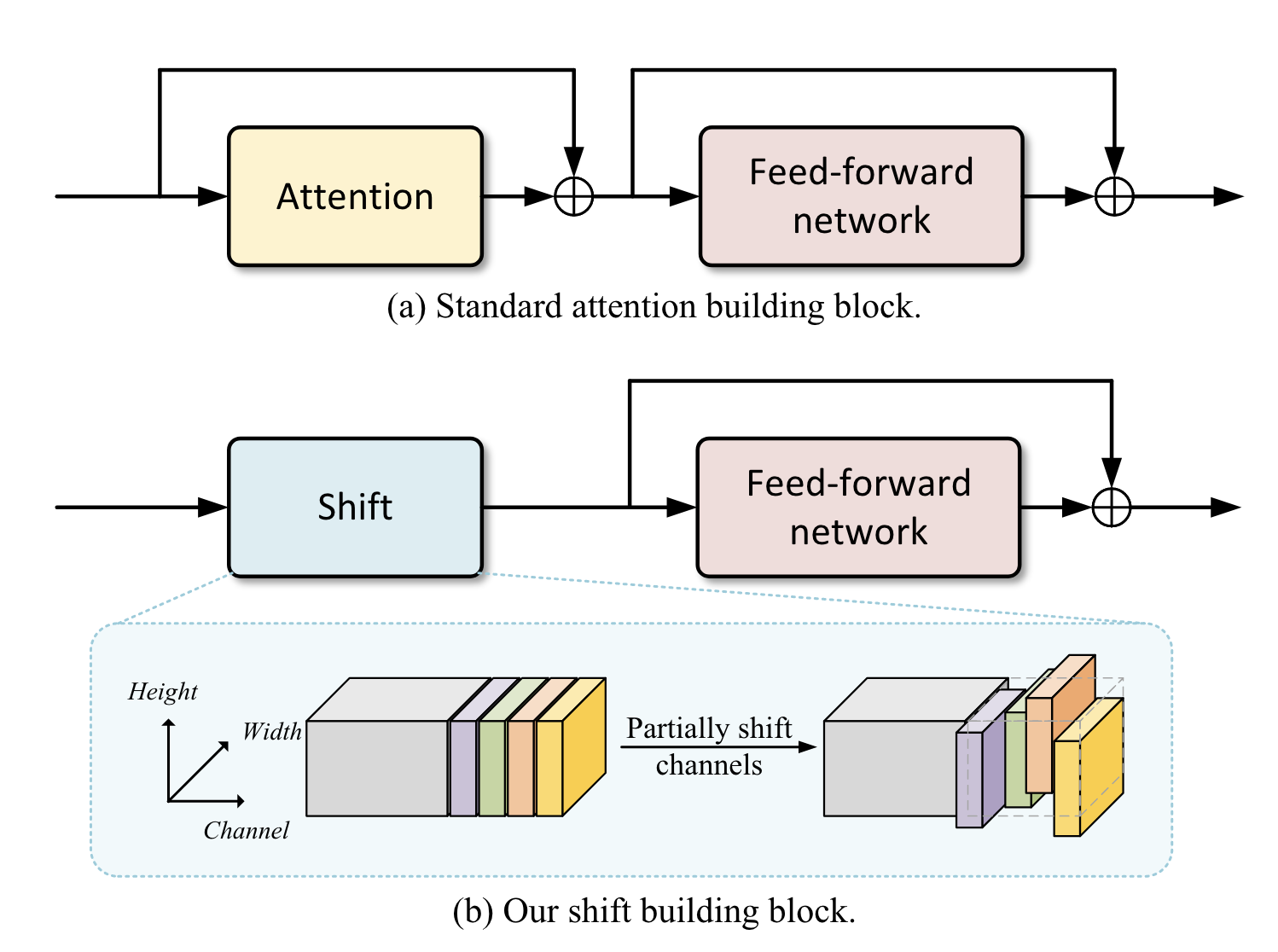
Related work
Shift operation
在2017年就被认为是空间卷积运算的替代操作——使用两个1*1卷积和一个shift操作可以近似k*k卷积。此外还有active shift、sparse shift和partial shift(本文采用的)等变体。
本文旨在利用partial shift来验证attention机制的有效性,类似的思路有:ShiftMLP、AS-MLP,但设计细节不同,其他方案构建的模块更加复杂。
Shift Operation Meets Vision Transformer
architecture overview
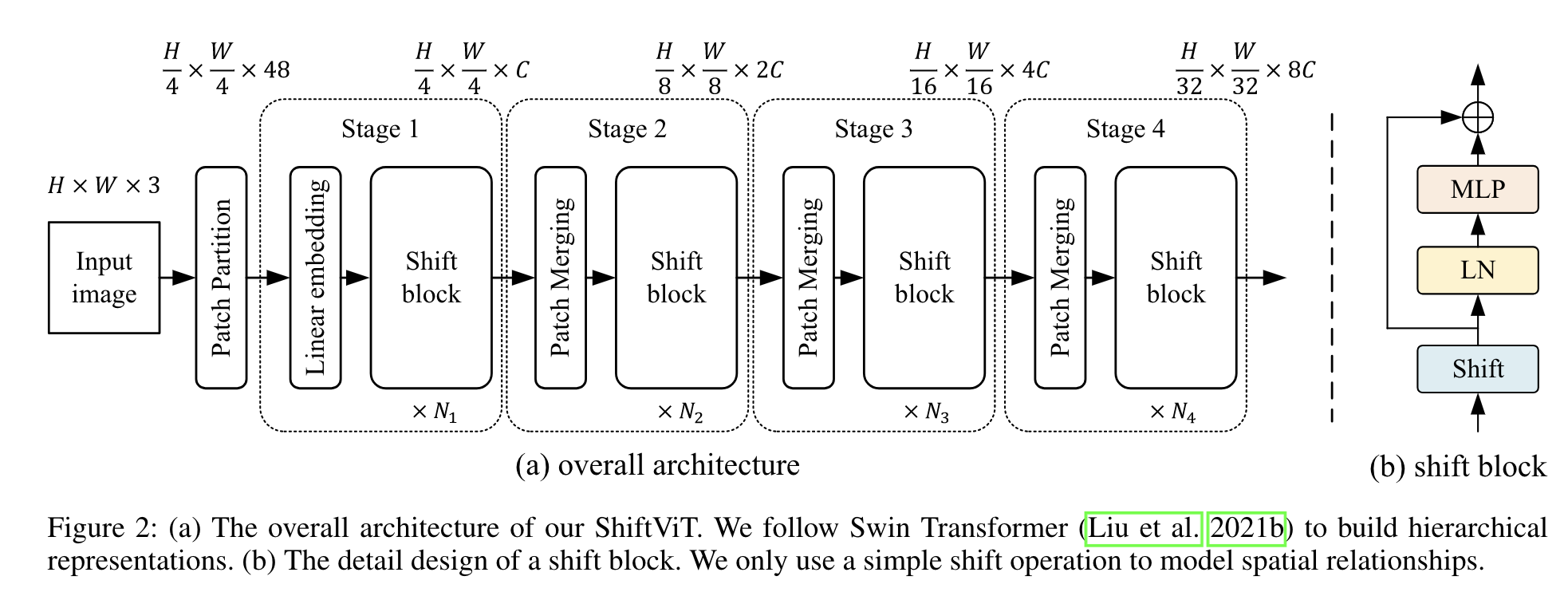
使用和Swin Transformer类似的架构。
- 给定$H\times W\times 3$的输入image,首先将其分为多个不重叠的patches,每个patch是$4\times 4$像素,即输出为$\frac{H}{4}\times\frac{W}{4}$个token,每个token有48个channel
- 之后的操作分为四步,每步包括embedding generation和stacked shift blocks
- embedding generation:用线性层将每个token转换为一个channel size为C的embedding,然后用kernel size为$2\times 2$的卷积整合相邻的patch,输出相当于降采样,但channel size从$C$变为$2C$
- stacked shift blocks:由重复的shift block构成——包含shift操作、layerNorm、MLP。实际上就是Transformer block中attention替换为shift,shift blocks的个数是可变的$N_i$。
- shift operation
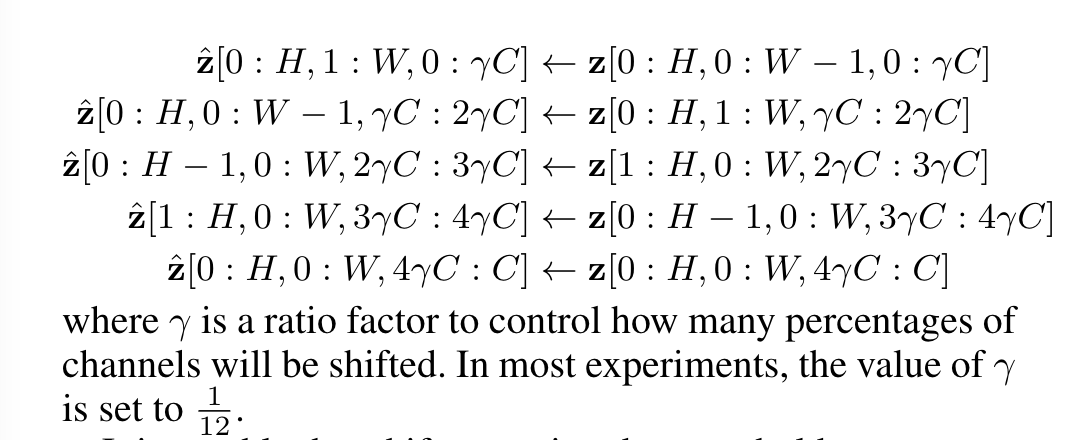
- shift operation
architecture varients
本文为了与Swin Transformer比较,设计了Shift-Tiny、Shift-Small、Shift-Base:
- Shift-Tiny:$C=96,\{N_i\}=\{6,8,18,6\},\gamma=1/12$
- Shift-Small:$C=96,\{N_i\}=\{10,18,36,10\},\gamma=1/12$
- Shift-Base:$C=128,\{N_i\}=\{10,18,36,10\},\gamma=1/16$
experiment
在图像分类的ImageNet-1K、目标检测的COCO、语义分割的ADE20k数据集上进行实验,取得如下结果:
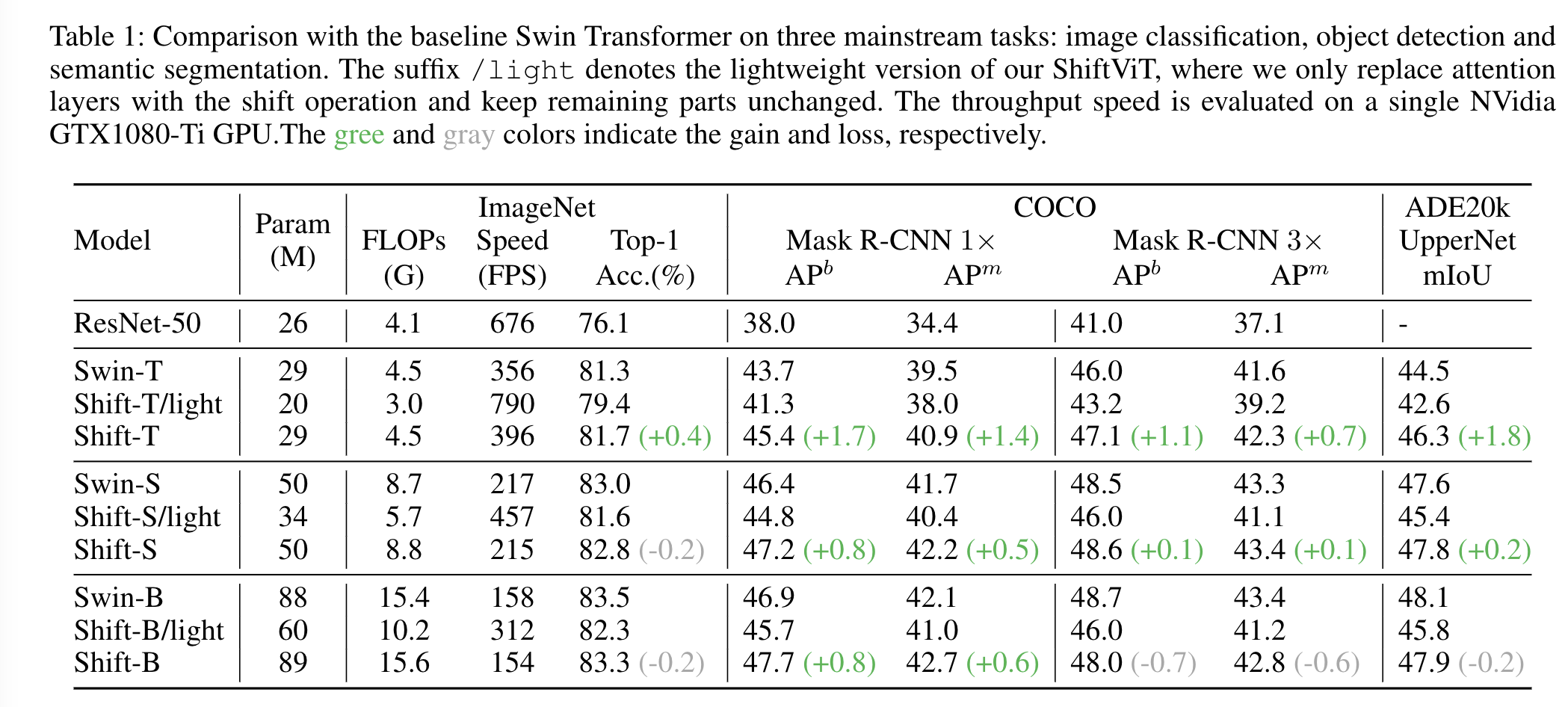
可以看到只替换attention的light模型在性能上有所下降,但由于运算的减少,light模型高效的多,与resnet相比则更强大也更高效。
通过添加更多的block来保证参数量持平的情况下,Shift模型取得了更好的结果。相比ShiftMLP、AS-MLP效果略好,说明简单的shift操作已经够好了。
conclusion
ViT中的attention实际上作用不大,其关键部分应该在FFN或者训练方案中。