来自百度和清华,提出为文本构建多个异质图的方法。
论文地址:https://arxiv.org/abs/2111.00180v1
现存问题
- 缺少上下文信息
- 知识不完整
- 文本语法不完整
- 缺少标注数据
现有方法
- HGAT STGCN忽略了同类型node的交互,且参数量很大
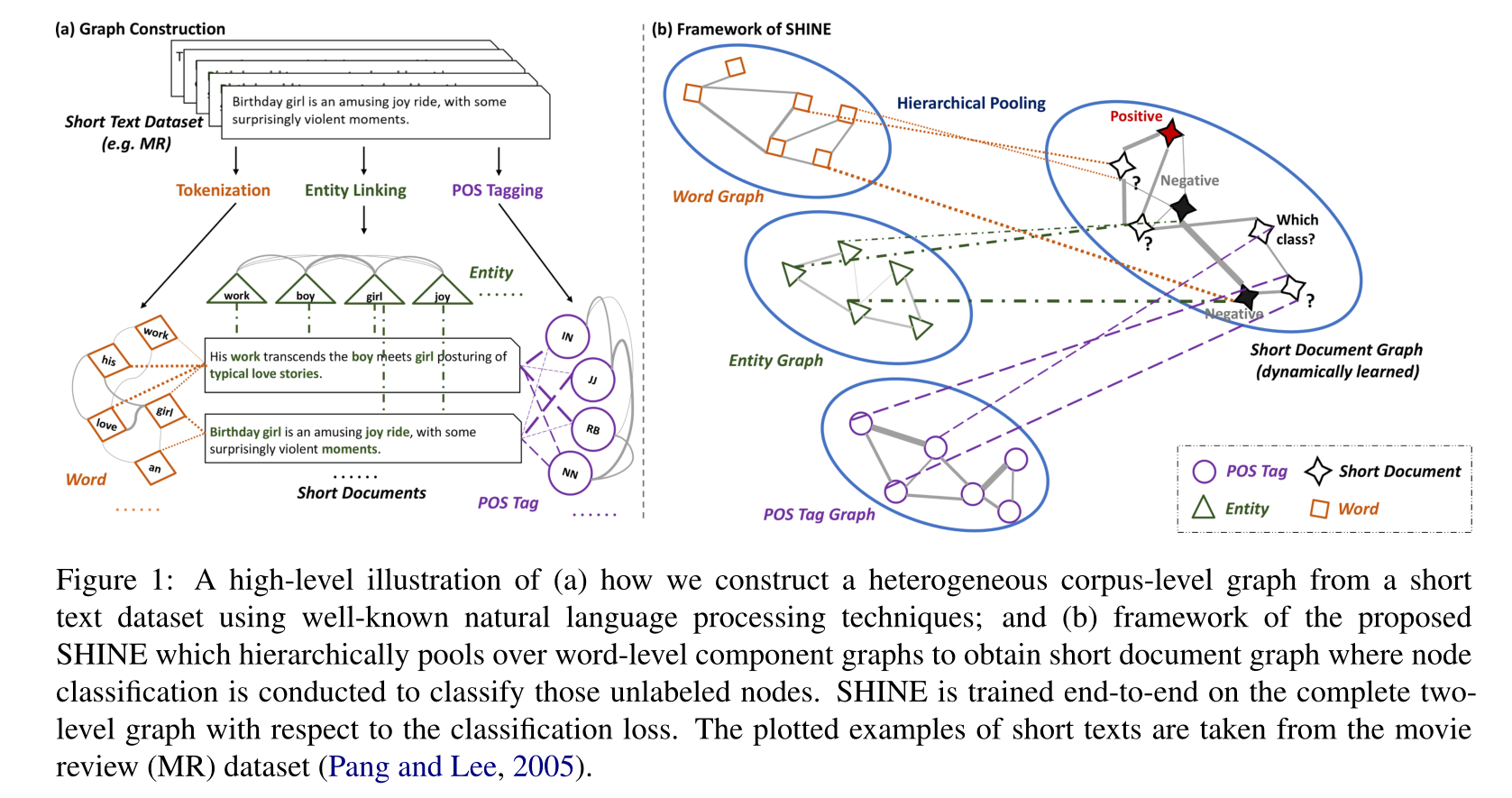
HIerarchical heterogeNEous graph representation learning(SHNIE)
word-level graph
- three types of word-level components
- words 包含语义信息
- part of speech(POS) tags 词性标注 语法信息
- entity 在KB中可以找到的对应实体 获取额外知识
node embedding
$G_\tau=\{V_\tau,A_\tau\}$表示类型$\tau$的word-level graph,特征为$X^\tau\in R^{|V_\tau|*d_\tau}$,用2-layer的GCN得到节点特征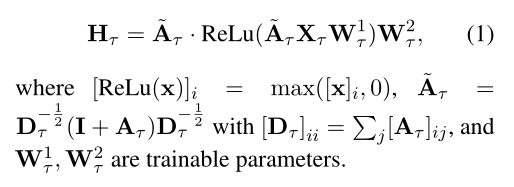
graph construction
word graph
基于co-occurance,(也可以额外利用语法的依赖)
基于PMI:point-wise mutual information计算邻接矩阵 $[A_w]_{ij}=max(0, PMI(v_w^i,v_w^j))$
可以concat预训练的word embedding,从而使用通用语义信息
one-hot embedding init
POS tag graph
与word graph相似,基于co-occurance和PMI,输入是所有word的POS(词性标注)
one-hot embedding init
entity graph
通过KG(文中是NELL)获得节点的实体集
实体数目很少,不适用co-occurance,使用cos相似度$[A_e]_{ij}=max(0, cossim(x_e^i,x_e^j))$
KG embedding init
short text graph
$G_s=\{V_s,A_s\}$,$v_s \in V_s$表示短文本。
利用层次池化,从word-level graph学习短文本间的相似性即$A_s$,传播label
hierarchical pooling over $G_\tau s$
$x_\tau^i=u(H_\tau^Ts_\tau^i)$ 其中$u(x)=x/||x||_2$归一
$s_\tau^i$计算如下:
$\tau = w\ or\ p$ word或POS tag graph: $[s_\tau^i]_j=TFIDF(v_\tau^j,v_s^i)$,用$s_\tau^i/\sum s_\tau^i$归一
$\tau = e$ entity graph: 如果$v_\tau^j$在$v_s^i$中,$[s_e^i]_j=1$,否则$[s_e^i]_j=0$。用$s_\tau^i/\sum s_\tau^i$归一
最后将三个embedding$x_w^i,x_p^i,x_e^i$ concat得到$x_s^i$(可以用LSTM、加权平均等)
dynamic graph learning
仍然使用2-layer GCN传播标签信息,更新$X_s$。
最终分类得分计算如下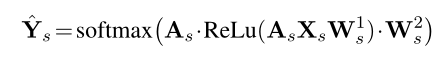
使用CEloss