From Princeton Chen Danqi,提出对比学习的sentence embedding学习框架 ,发表在EMNLP2021。
论文地址: https://arxiv.org/pdf/2104.08821.pdf
开源代码: https://github.com/princeton-nlp/SimCSE
introduction
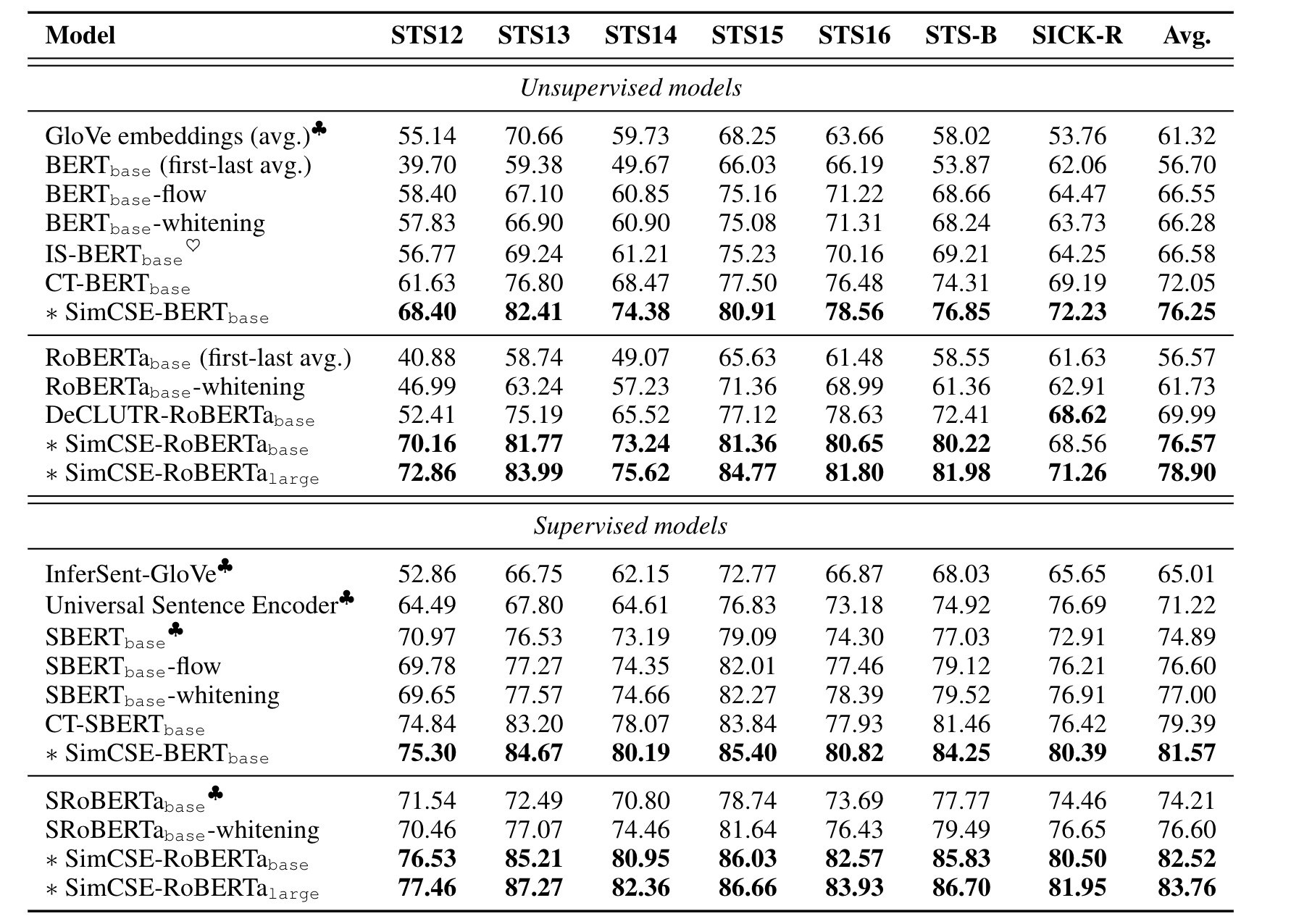
本文提出了SOTA的sentence embedding方法——SimCSE,在有监督和无监督的情况下都取得了较好的表现,并证明了对比学习和预训练LM结合的有效性。
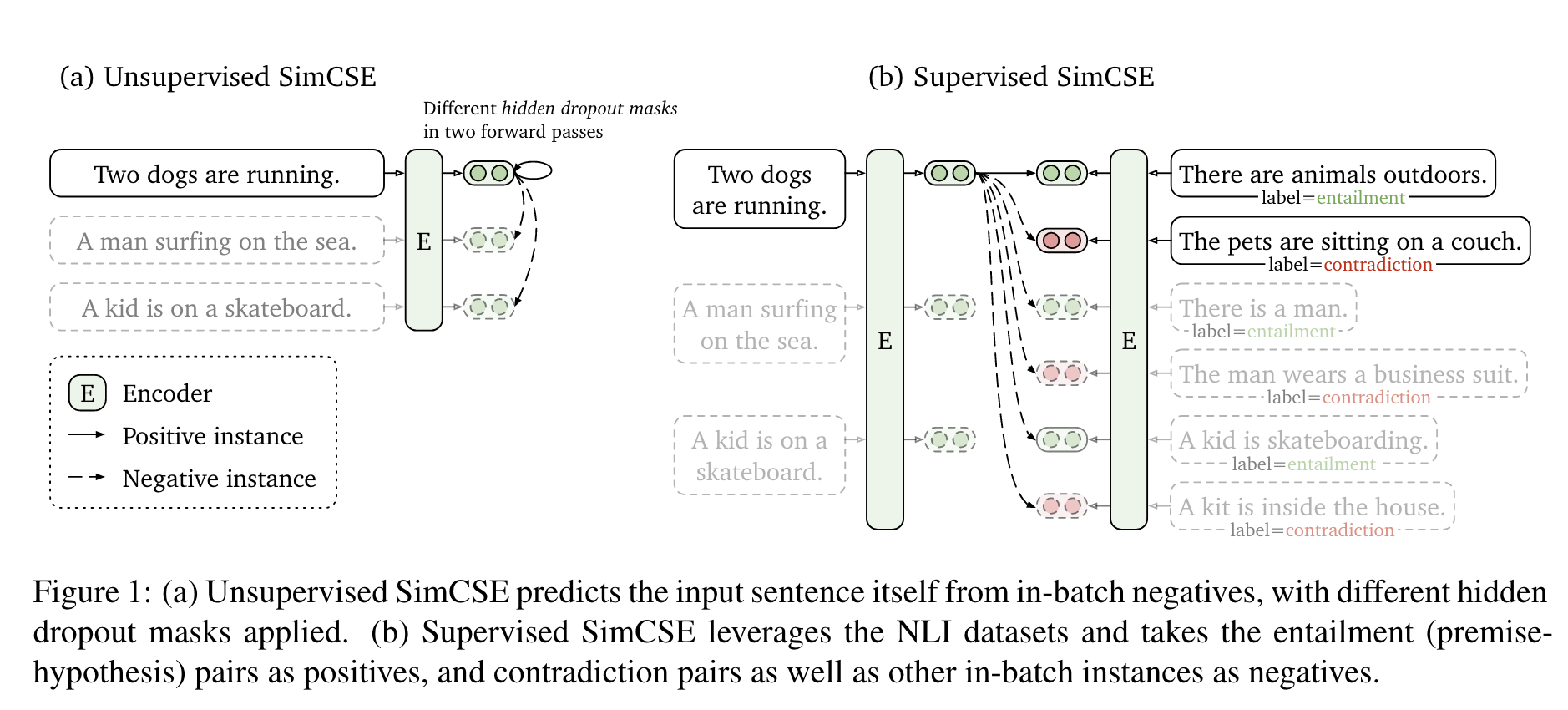
无监督的SimCSE为sentence本身做了dropout以引入噪声,然后让模型预测该sentence。分别对同一sentence做两次dropout并输入预训练模型,可以得到两个不同的embedding——“positive pairs”,然后去batch中的其他sentence作为”negative”,让模型预测positive。
有监督的SimCSE将标注句子pairs用于对比学习。与之前的三分类不同(entaiment蕴含、neutral中性、contradiction矛盾),本文认为蕴含关系可以看做正样本,并发现通过添加矛盾关系作为负样本
background
contrastive learning
通过把语义上相近的邻居push together、不相近的则push apart来学习有效的表示。
- paired examples:$\mathcal{D}=\{(x_i, x_i^+)\}_{i=1}^m$
$h_i,h_i^+$为$x_i,x_i^+$的表示,则loss为
$\mathcal{l}_i=-{\rm log}\frac{e^{sim(h_i,h_i^+)/\tau}}{\Sigma_{j=1}^Ne^{sim(h_i,h_j^+)/\tau}}$如何构建$(x_i,x_i^+)$这样的pair
- 在CV中可以通过图像裁剪、翻转、扭曲等随机变换生成
- 在NLP中可以通过单词删除、重排、替换生成
Unsupervised SimCSE
- 简单地令$x_i^+=x_i$,然后对二者分别加dropout mask
- encoder: $h_i^z=f_\theta(x_i,z),z\text{ is mask}$
- 让原始输入通过两次encoder即可生成pairs
- 本文中实验了其他数据增强方案,不如dropout
Supervised SimCSE
- 使用NLI数据集,将矛盾关系作为负样本,蕴含关系作为正样本
- 得到$(x_i,x_i^+)$或$(x_i,x_i^+,x_i^-)$这样的pairs
- loss: $-{\rm log}\frac{e^{sim(h_i,h_i^+)/\tau}}{\Sigma_{j=1}^N(e^{sim(h_i,h_j^+)/\tau}+e^{sim(h_i,h_j^-)/\tau})}$
使用dual-encoder框架反而降低了性能
对比学习也有助于解决embedding不对称的问题——向量应该均匀分布在空间中
experiment