前言
深度学习大热之后发展出各种神经网络,我虽然之前接触过相关的一些模型,但知识零零散散,感觉一头雾水。这篇文章主要涉及一些基本的神经网络模型,旨在加强对这些模型的系统认知。
有监督的神经网络(Supervised Neural Networks)
NN和DNN
NN的基础模型是感知机(Perceptron),因此NN也可以叫做多层感知机(Multi-layer Perceptron,MLP)。单层感知机叫做感知机,多层感知机(MLP)≈人工神经网络(ANN)。
网络的层数直接决定了其对现实的刻画能力——利用每层更少的神经元拟合更复杂的函数。但层数加深意味着:
- “梯度消失”(gradient vanish)更加严重,反向传播梯度时,梯度指数衰减导致低层几乎接收不到信号;
- 更容易陷入局部最优而越来越偏离全局最优。在数据量不足时,深层网络的性能甚至不如浅层网络;
- 更容易过拟合。
一般来说,多个隐藏层(通常为超过5层)的NN都可以叫做DNN,NN的结构指神经元的连接方式,下图为3种不同的例子,神经元的连接可以是任意深度的。
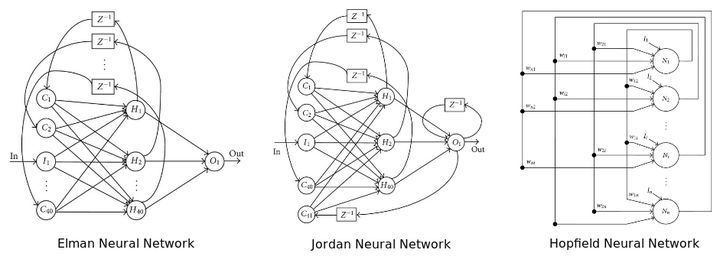
图片来源:10 Misconceptions about Neural Networks
DNN可以解决大部分分类任务,但是DNN的参数量很大,需要的数据量也很大,因此纯粹的全连接层应用性不强。(CNN和RNN一般结构都比较深;AE则可以是浅层或深层的,所以会有Deep Auto Encoder这样的词汇而通常没有Deep CNN/RNN。)
CNN
CNN的精髓是在多个空间位置上共享参数,从而压缩输入端的维度,避免参数数量的膨胀。
- 以“卷积核”为上下层神经元提供间接连接方式。
- 通过卷积和池化,在压缩维度的同时,挖掘和提取了局部结构的特征。

CNN的输入通常和图片联系,实际上,CNN可以处理大部分格状结构化数据(Grid-like Data)。例如,图片像素是二维的格状数据,时间序列在等时间上抽取相当于一维的的格状数据,而视频数据可以理解为对应视频帧宽度、高度、时间的三维数据。
循环神经网络(Recurrent NN)和递归神经网络(Recursive NN)
这两种网络通常都叫RNN,虽然网络结构不同,但是都可以处理序列问题。在RNN中,每一层在t时刻的输入,不仅包含上一层在t时刻的输出,还包含自身在t-1时刻的输出,如下图所示,某一时刻的输出,理论上由该时刻和之前的所有输入决定,换言之,RNN拥有“记忆”能力,可以学习序列间的依赖关系。
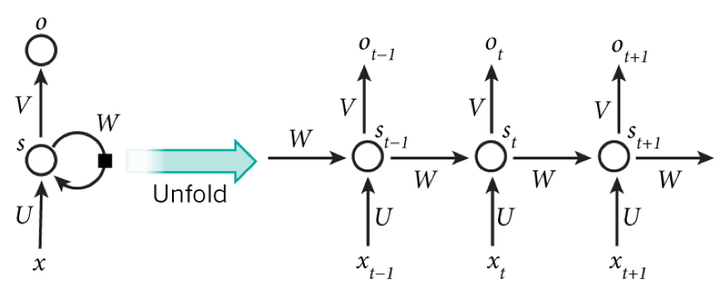
RNN实际上可以看成一个在时间上传递的网络,时间序列长度就是它的深度。那么问题来了,“gradient vanish”也会在RNN的时间轴上出现,ft反向传播梯度时,并不足以影响遥远的过去,因此ML领域发展出了LSTM(Long Short-term Memory)。
LSTM处理序列问题有效的关键在于Gate,Gate是一种让信息选择式通过的方法。
- forget gate: 控制上一时刻cell状态ct-1有多少保留到ct;
- input state: 控制当前时刻网络输入xt-1有多少保存到ct;
- output: 控制当前时刻cell状态ct有多少输出到ht;
类似地,Bi-RNN(双向RNN)中“现在”依赖于“过去”和“未来”,可以使输出取决于上下文,常在NLP和语音分析中使用。Recursive NN和Recurrent NN结构不同,是树状而不是网状,可以用树状降低序列的长度。
无监督的预训练网络(Unsupervised Pre-trained Neural Networks)
深度生成模型(Deep Generative Models)
玻尔兹曼机(Boltzmann Machines)与RBM
BM是一个基于能量的模型,能量越小,对应状态的概率越大。对于给定数据集,如果不知道潜在的分布形式,则学习过程是非常困难的,但是统计力学的结论表明,任何概率分布都可以转变成基于能量的模型,这是一种学习概率分布的方法。
RBM限定了其结构必须是二分图(Biparitite Graph)且隐藏层和可观测层之间不可以相连接。
深度信念网络(Deep Belief Neural Networks)
DBN由两个部分/阶段组成:
- 用堆叠的受限玻尔兹曼机(Stacked RBM)进行预训练(unsupervised),用于特征抽取并重建。
- 用一层普通的前馈网络进行微调,用于学习得到的复杂特征。
生成式对抗网络(Generative Adversarial Networks)
GAN同时训练两个模型(体现了博弈论的思想):
- 生成网络Generator: 用于生成图片使其与训练数据类似,一般是deconvolutional layer。
- 判别网络Discriminator:用于判断生成的图片是训练数据还是伪装的数据,一般是CNN。
自编码器(Auto-encoder)
AE主要有两个部分:
- Encoder
- Decoder

模型学习的是中间的低维压缩表示,并以重建误差来评估AE的性能。实际上AE主要用于降维,与PCA类似,从高维原始数据中提取低维特征。